A common occurrence in programming are problems that seem simple on the surface but become increasingly complicated the longer you look at them. While working on the latest version of the Recent Posts Plus WordPress plugin I stumbled upon a variety of issues with text/html truncation which I hope to outline in this post. So lets start with text truncation…
Truncating Text
There are two ways in which I needed to truncate text; by the number of characters, and by the number of words.
Original text:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque tellus enim, iaculis eget imperdiet et, sodales id magna.
Limited to 9 chars:
Lorem ips
123456789
Limited to 9 words:
Lorem ipsum dolor sit amet, consectetur adipiscing elit. Quisque
1 2 3 4 5 6 7 8 9
Truncating Text by Char
The function to truncate text by char is very simple.
function truncate_chars($text, $limit, $ellipsis = '...') {
if( strlen($text) > $limit )
$text = trim(substr($text, 0, $limit)) . $ellipsis;
return $text;
}
Basically you just count the number of chars using strlen if the length is greater than the limit then return a subset of the string.
You can improve this function by preventing it from chopping a word in half by searching the string for the next white space character.
function truncate_chars($text, $limit, $ellipsis = '...') {
if( strlen($text) > $limit ) {
$endpos = strpos(str_replace(array("\r\n", "\r", "\n", "\t"), ' ', $text), ' ', $limit);
if($endpos !== FALSE)
$text = trim(substr($text, 0, $endpos)) . $ellipsis;
}
return $text;
}
Just one little note about these functions they aren’t multibyte safe. If you need to perform truncation of multibyte strings (Korean, Chinese, Japanese, etc) then look into using the multibyte string functions instead http://php.net/ref.mbstring.
Truncating Text by Word
Truncating text by words is fairly simple as well we just break the text into pieces using whitespace characters as the separator. However I have come across a few potential pitfalls. The obvious way to break the text into words is like this $words = explode(' ', $text, $limit + 1);. However the issue with this is that it doesn’t take into account all whitespace characters (like tabs and line breaks).
The way that WordPress and a lot of other people do it is like this:
function truncate_words($text, $limit, $ellipsis = '...') {
$words = preg_split("/[\n\r\t ]+/", $text, $limit + 1, PREG_SPLIT_NO_EMPTY);
if ( count($words) > $limit ) {
array_pop($words);
$text = implode(' ', $words);
$text = $text . $excerpt_more;
}
return $text;
}
Which works well however it has one major issue in that if you feed it text containing line breaks or tabs it will replace those line breaks with normal spaces ‘ ‘. The better way to do it is rather than using implode on the word array, capture the offset of the last word using the PREG_SPLIT_OFFSET_CAPTURE flag then use this offset to split the string.
function truncate_words($text, $limit, $ellipsis = '...') {
$words = preg_split("/[\n\r\t ]+/", $text, $limit + 1, PREG_SPLIT_NO_EMPTY|PREG_SPLIT_OFFSET_CAPTURE);
if (count($words) > $limit) {
end($words); //ignore last element since it contains the rest of the string
$last_word = prev($words);
$text = substr($text, 0, $last_word[1] + strlen($last_word[0])) . $ellipsis;
}
return $text;
}
This method ensures that the integrity of the whitespace is retained. It is also significantly faster (see performance comparison at the end of the post).
Truncating with CSS
One interesting thing about all of this is that in many cases text truncation should really be handled at the client side. It makes sense that the page contains the full-text data but trims it if the content area is too small to hold everything when displayed.
A good example to illustrate this is imagine if you design a menu which contains a list of items. Now the width of the menu is fixed so some items may need to be truncated to fit the width of the list. However if the user can adjust the font size suddenly the list needs to be remade server-side to compensate for presentation changes. You can also run into issues if the font is not monospaced (monospaced = each character has same width) since limiting the number of characters won’t result in a consistent width.
In this case truncation can be handled with the CSS text-overflow property.

As the below code shows it is very easy to implement and is fairly well supported (IE6, Opera 9+, Safari, Chrome)
p {
white-space: nowrap;
width: 250px;
overflow: hidden;
-o-text-overflow: ellipsis;
-ms-text-overflow: ellipsis;
text-overflow: ellipsis;
}
See http://developer.mozilla.org/en/CSS/text-overflow for more info.
However this doesn’t work at all if you apply it to a DIV which contains nested elements. The nested elements will be clipped without an ellipsis being appended. You can workaround this issue by applying the same styles to all the nested elements.
#mydiv, #mydiv * {
white-space: nowrap;
width: 250px;
overflow: hidden;
-o-text-overflow: ellipsis;
-ms-text-overflow: ellipsis;
text-overflow: ellipsis;
}
Truncating HTML
Ok so now we get to the tricky part. The issue with truncating HTML is that you cannot use an approach similar to what you would use for plain text. The reason for this is obvious if you truncate HTML as text then you run the risk of splitting the text in the middle of a HTML tag or attribute. So what we need is to be able to differentiate between the HTML tags and text, this requires parsing the HTML.
If you look online you will find some solutions to this problem that use regular expressions to parse the HTML. Parsing HTML with regular expressions is a bad idea if you are interested in how HTML is parsed by browsers then have a look at How Browsers Work: Behind the Scenes of Modern Web Browsers.
Fortunately the PHP DomDocument class can handle all the difficult parsing for us. So what we want is to parse the HTML using DomDocument that way we can accurately traverse the DOM and count the number of characters or words in any of the text nodes. Then we can remove any superfluous nodes and reconstruct the HTML document.
class TruncateHTML {
public static function truncateChars($html, $limit, $ellipsis = '...') {
if($limit <= 0 || $limit >= strlen(strip_tags($html)))
return $html;
$dom = new DOMDocument();
$dom->loadHTML($html);
$body = $dom->getElementsByTagName("body")->item(0);
$it = new DOMLettersIterator($body);
foreach($it as $letter) {
if($it->key() >= $limit) {
$currentText = $it->currentTextPosition();
$currentText[0]->nodeValue = substr($currentText[0]->nodeValue, 0, $currentText[1] + 1);
self::removeProceedingNodes($currentText[0], $body);
self::insertEllipsis($currentText[0], $ellipsis);
break;
}
}
return preg_replace('~<(?:!DOCTYPE|/?(?:html|head|body))[^>]*>\s*~i', '', $dom->saveHTML());
}
public static function truncateWords($html, $limit, $ellipsis = '...') {
if($limit <= 0 || $limit >= self::countWords(strip_tags($html)))
return $html;
$dom = new DOMDocument();
$dom->loadHTML($html);
$body = $dom->getElementsByTagName("body")->item(0);
$it = new DOMWordsIterator($body);
foreach($it as $word) {
if($it->key() >= $limit) {
$currentWordPosition = $it->currentWordPosition();
$curNode = $currentWordPosition[0];
$offset = $currentWordPosition[1];
$words = $currentWordPosition[2];
$curNode->nodeValue = substr($curNode->nodeValue, 0, $words[$offset][1] + strlen($words[$offset][0]));
self::removeProceedingNodes($curNode, $body);
self::insertEllipsis($curNode, $ellipsis);
break;
}
}
return preg_replace('~<(?:!DOCTYPE|/?(?:html|head|body))[^>]*>\s*~i', '', $dom->saveHTML());
}
private static function removeProceedingNodes(DOMNode $domNode, DOMNode $topNode) {
$nextNode = $domNode->nextSibling;
if($nextNode !== NULL) {
self::removeProceedingNodes($nextNode, $topNode);
$domNode->parentNode->removeChild($nextNode);
} else {
//scan upwards till we find a sibling
$curNode = $domNode->parentNode;
while($curNode !== $topNode) {
if($curNode->nextSibling !== NULL) {
$curNode = $curNode->nextSibling;
self::removeProceedingNodes($curNode, $topNode);
$curNode->parentNode->removeChild($curNode);
break;
}
$curNode = $curNode->parentNode;
}
}
}
private static function insertEllipsis(DOMNode $domNode, $ellipsis) {
$avoid = array('a', 'strong', 'em', 'h1', 'h2', 'h3', 'h4', 'h5'); //html tags to avoid appending the ellipsis to
if( in_array($domNode->parentNode->nodeName, $avoid) && $domNode->parentNode->parentNode !== NULL) {
// Append as text node to parent instead
$textNode = new DOMText($ellipsis);
if($domNode->parentNode->parentNode->nextSibling)
$domNode->parentNode->parentNode->insertBefore($textNode, $domNode->parentNode->parentNode->nextSibling);
else
$domNode->parentNode->parentNode->appendChild($textNode);
} else {
// Append to current node
$domNode->nodeValue = rtrim($domNode->nodeValue).$ellipsis;
}
}
private static function countWords($text) {
$words = preg_split("/[\n\r\t ]+/", $text, -1, PREG_SPLIT_NO_EMPTY);
return count($words);
}
}View the above source code standalone
View old source code standalone (version 1)
/**
* Iterates individual words of DOM text and CDATA nodes
* while keeping track of their position in the document.
*
* Example:
*
* $doc = new DOMDocument();
* $doc->load('example.xml');
* foreach(new DOMWordsIterator($doc) as $word) echo $word;
*
* @author pjgalbraith http://www.pjgalbraith.com
* @author porneL http://pornel.net (based on DOMLettersIterator available at http://pornel.net/source/domlettersiterator.php)
* @license Public Domain
*
*/
final class DOMWordsIterator implements Iterator {
private $start, $current;
private $offset, $key, $words;
/**
* expects DOMElement or DOMDocument (see DOMDocument::load and DOMDocument::loadHTML)
*/
function __construct(DOMNode $el)
{
if ($el instanceof DOMDocument) $this->start = $el->documentElement;
else if ($el instanceof DOMElement) $this->start = $el;
else throw new InvalidArgumentException("Invalid arguments, expected DOMElement or DOMDocument");
}
/**
* Returns position in text as DOMText node and character offset.
* (it's NOT a byte offset, you must use mb_substr() or similar to use this offset properly).
* node may be NULL if iterator has finished.
*
* @return array
*/
function currentWordPosition()
{
return array($this->current, $this->offset, $this->words);
}
/**
* Returns DOMElement that is currently being iterated or NULL if iterator has finished.
*
* @return DOMElement
*/
function currentElement()
{
return $this->current ? $this->current->parentNode : NULL;
}
// Implementation of Iterator interface
function key()
{
return $this->key;
}
function next()
{
if (!$this->current) return;
if ($this->current->nodeType == XML_TEXT_NODE || $this->current->nodeType == XML_CDATA_SECTION_NODE)
{
if ($this->offset == -1)
{
$this->words = preg_split("/[\n\r\t ]+/", $this->current->textContent, -1, PREG_SPLIT_NO_EMPTY|PREG_SPLIT_OFFSET_CAPTURE);
}
$this->offset++;
if ($this->offset < count($this->words)) {
$this->key++;
return;
}
$this->offset = -1;
}
while($this->current->nodeType == XML_ELEMENT_NODE && $this->current->firstChild)
{
$this->current = $this->current->firstChild;
if ($this->current->nodeType == XML_TEXT_NODE || $this->current->nodeType == XML_CDATA_SECTION_NODE) return $this->next();
}
while(!$this->current->nextSibling && $this->current->parentNode)
{
$this->current = $this->current->parentNode;
if ($this->current === $this->start) {$this->current = NULL; return;}
}
$this->current = $this->current->nextSibling;
return $this->next();
}
function current()
{
if ($this->current) return $this->words[$this->offset][0];
return NULL;
}
function valid()
{
return !!$this->current;
}
function rewind()
{
$this->offset = -1; $this->words = array();
$this->current = $this->start;
$this->next();
}
}View the above source code standalone
/**
* Iterates individual characters (Unicode codepoints) of DOM text and CDATA nodes
* while keeping track of their position in the document.
*
* Example:
*
* $doc = new DOMDocument();
* $doc->load('example.xml');
* foreach(new DOMLettersIterator($doc) as $letter) echo $letter;
*
* NB: If you only need characters without their position
* in the document, use DOMNode->textContent instead.
*
* @author porneL http://pornel.net
* @license Public Domain
*
*/
final class DOMLettersIterator implements Iterator
{
private $start, $current;
private $offset, $key, $letters;
/**
* expects DOMElement or DOMDocument (see DOMDocument::load and DOMDocument::loadHTML)
*/
function __construct(DOMNode $el)
{
if ($el instanceof DOMDocument) $this->start = $el->documentElement;
else if ($el instanceof DOMElement) $this->start = $el;
else throw new InvalidArgumentException("Invalid arguments, expected DOMElement or DOMDocument");
}
/**
* Returns position in text as DOMText node and character offset.
* (it's NOT a byte offset, you must use mb_substr() or similar to use this offset properly).
* node may be NULL if iterator has finished.
*
* @return array
*/
function currentTextPosition()
{
return array($this->current, $this->offset);
}
/**
* Returns DOMElement that is currently being iterated or NULL if iterator has finished.
*
* @return DOMElement
*/
function currentElement()
{
return $this->current ? $this->current->parentNode : NULL;
}
// Implementation of Iterator interface
function key()
{
return $this->key;
}
function next()
{
if (!$this->current) return;
if ($this->current->nodeType == XML_TEXT_NODE || $this->current->nodeType == XML_CDATA_SECTION_NODE)
{
if ($this->offset == -1)
{
// fastest way to get individual Unicode chars and does not require mb_* functions
preg_match_all('/./us',$this->current->textContent,$m); $this->letters = $m[0];
}
$this->offset++; $this->key++;
if ($this->offset < count($this->letters)) return;
$this->offset = -1;
}
while($this->current->nodeType == XML_ELEMENT_NODE && $this->current->firstChild)
{
$this->current = $this->current->firstChild;
if ($this->current->nodeType == XML_TEXT_NODE || $this->current->nodeType == XML_CDATA_SECTION_NODE) return $this->next();
}
while(!$this->current->nextSibling && $this->current->parentNode)
{
$this->current = $this->current->parentNode;
if ($this->current === $this->start) {$this->current = NULL; return;}
}
$this->current = $this->current->nextSibling;
return $this->next();
}
function current()
{
if ($this->current) return $this->letters[$this->offset];
return NULL;
}
function valid()
{
return !!$this->current;
}
function rewind()
{
$this->offset = -1; $this->letters = array();
$this->current = $this->start;
$this->next();
}
}View the above source code standalone (Note the DOMLettersIterator class was created by pornel)
Well I didn’t say it was going to be easy. As you can see it takes a fair bit of work to do and a lot more lines of code compared to the simple text truncate functions. It is also significantly more expensive to process.
You can use the above class like this:
require('DOMLettersIterator.php');
require('DOMWordsIterator.php');
require('TruncateHTML.php');
$html = '<p>This is <strong>test</strong> html text.</p>';
$output = TruncateHTML::truncateChars($html, '11', '...');
echo $output;
$output = TruncateHTML::truncateWords($html, '3', '...');
echo $output;
In summary if you need to truncate HTML I would always recommend you first consider whether it is possible to strip the tags and process it as plain text. Of course you could always throw caution to the wind and devise a rudimentary regex based solution, which may work ok if you can live with the limitations. Otherwise the above approach (or something similar to it) is a good option especially if accuracy is important.
Performance Comparison
The following numbers represent the average execution time in microseconds to execute each function 1000 times. Smaller is better.
truncate_chars: 1,446
truncate_chars2: 4,858 (second version that retains words)
truncate_words: 23,401 (WordPress version)
truncate_words2: 12,562
TruncateHTML::truncateChars: 874,875
TruncateHTML::truncateWords: 1,397,687
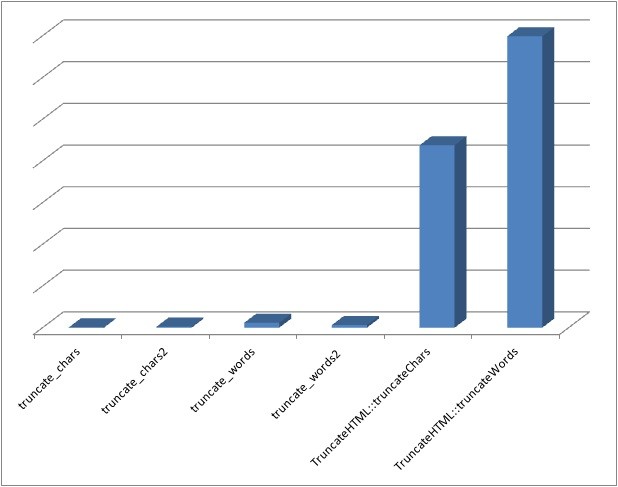
As you can see the HTML truncation functions are over 100 times slower than their text equivalents so you definitely want to consider caching their output.
Good blog post Patrick. I enjoyed reading it and learned some things.
Thanks and greetings to Adelaide, go you mighty crows.
Thanks a lot !
It’s very useful !
Just one modification:
//Replace $dom->loadHTML($html); to
$dom->loadHTML(mb_convert_encoding($html, 'HTML-ENTITIES', 'UTF-8'));
//The result
$html = TruncateHTML::truncateChars($html, '11', '...');
$html = html_entity_decode($html);
Thank you victor, without that line UTF-8 will be broken.
Hello Patrick!
Thank you for your article!
I’m looking for a way to insert a code inside marked up text. Is it possitble to use your classes for it?
The main idea is to insert code after N words, not tag, or for example dot.. So i somehow need to insert that code into the text without breaking the Markup.
Thankyou very much. Awesome.
I had to use html “more … ” link so I did it like this
$text = TruncateHTML::truncateChars($text, $chars, 'x1y1z2');
$text = str_replace('x1y1z2', $more_link, $text);
Its work for me. Thanks a lot:)
This is exactly what I needed. Thank you so very much!
Occasionally, these games are intriguing only when performed inside
the business of additional enthusiasts.
How can I insert instead … html code?
for example